
Yesterday Hostgator had a major outage in one of it’s Utah datacenters which caused a number of customers to be offline for several hours. The outage actually impacted Hostgator, Hostmonster, Justhost, Bluehost, and possibly more, but this post regards the Hostgator response specifically.
These companies all provide shared webhosting services. I am neither a client nor an employee of any of the businesses, though I do know people who are.
The company I do work for has had it’s share of outages, and I am doing what internally to help improve our own practices when outages happen, and I will consider following up on this with my manager next week to see if we can learn anything from it. What I saw during the outage, as an outsider, is interesting. There were three outlets of information provided, which we’ll analyze.
The first is the Hostgator Support Boards, their public forums where users can ask each other for help and the staff can jump in and provide assistance also. There was a thread about the outage, I’ve taken an excerpt (original):
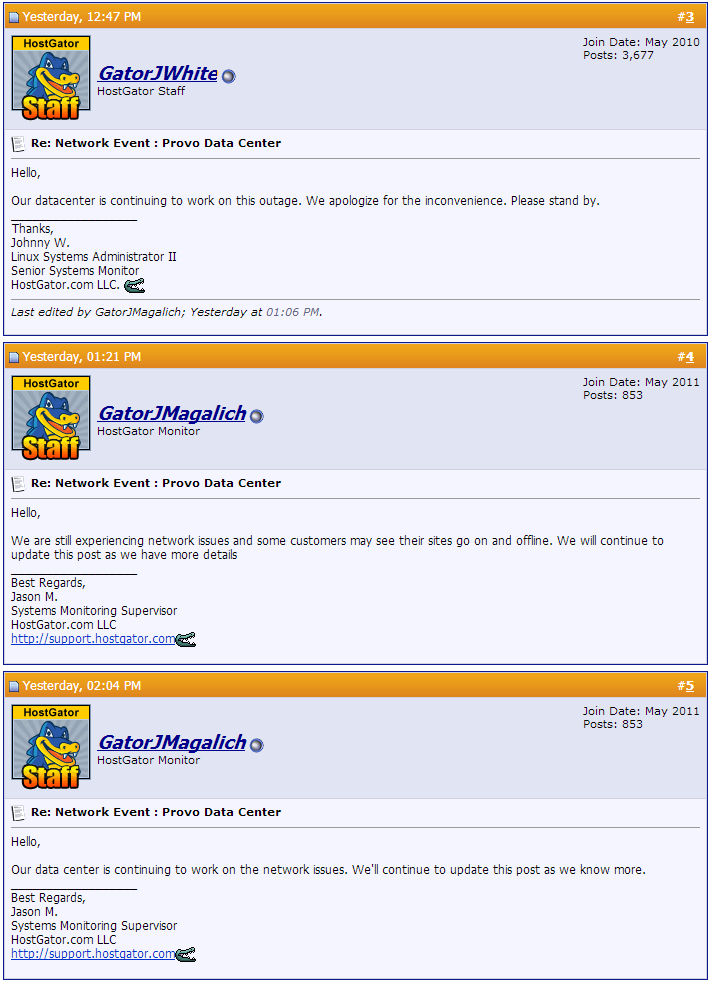
The thing that stands out most is that it is really the same update over and over again, no new information is being provided to the customer. This might work just fine for brief outages, but when the initial outage notification is at 10:30am, to be providing the same details until 4pm with nothing of substance in between is unacceptable. For six hours forum users were told by this thread that “the issue is ongoing, and our staff are working to resolve it” in several forms and variations.
Another outlet of information was the HostGator Twitter account (here), which had the following to say (note it is in reverse, captured 1pm EDT today, Saturday):
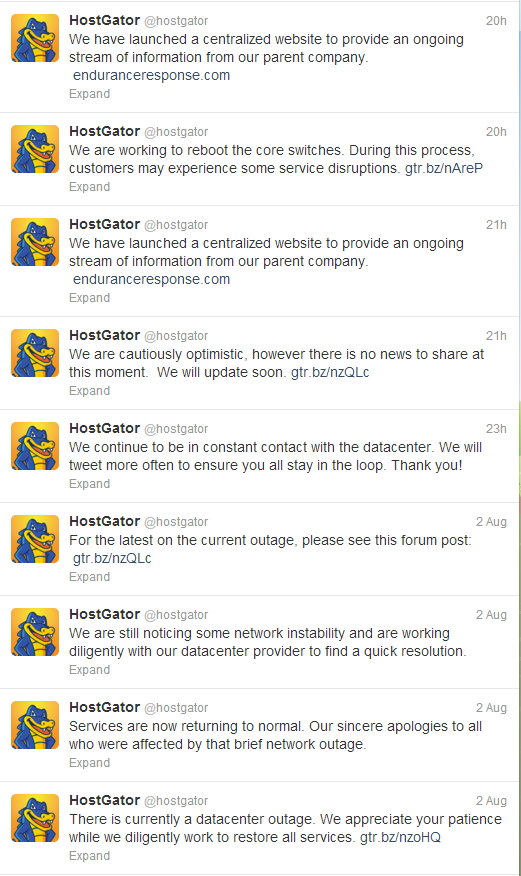
Times are based on EDT:
Again, an initial report just after 9am, followed shortly by an (incorrect) report at 9:40am that things are returning to normal. At 10:45am the outage is announced and at midday users are then directed to the above forum post, which has no details worth anything to someone wondering why their site has been down for hours. Still no useful news via Twitter, until at just before 4pm they announce a new site to provide updates.
And so we reach the third source of information, found here, which had updates every half hour from 3:30pm to 6pm, when the issues were finally resolved for the day. This is the only source where useful data for the technically minded could be found.

It turns out there were issues with both core switches at the facility which brought the entire network down. Not only did it take 8-9 hours to fix, it also took 6 hours for the company to provide any useful information as to what the problem was and what was being done to fix it.
Providers should look at this stream of communication and consider whether they would find it acceptable, and review how they handle their own outages. I have been in this situation as a customer, albeit with a different provider. If there is an outage for 10 minutes, I can be quickly placated with a “there is an issue, we’re working on it.” If the outage extends anywhere beyond about an hour, I want to know what is wrong and what is being done to fix it. Not because I want inside information, I want you to demonstrate that you are competent to find and fix the problem – this is what gives me confidence to continue using your service after the issue is fixed. And if your service is down beyond 2 or 3 hours, I am going to expect new useful updates at least hourly, ideally more often, so that I can follow the progression of solving the problem.
For me as a customer, it isn’t that your service went down, I understand things break. It is more important that you provide honest and useful details on why it is down and when you expect to have it fixed, even if these things are subject to change.